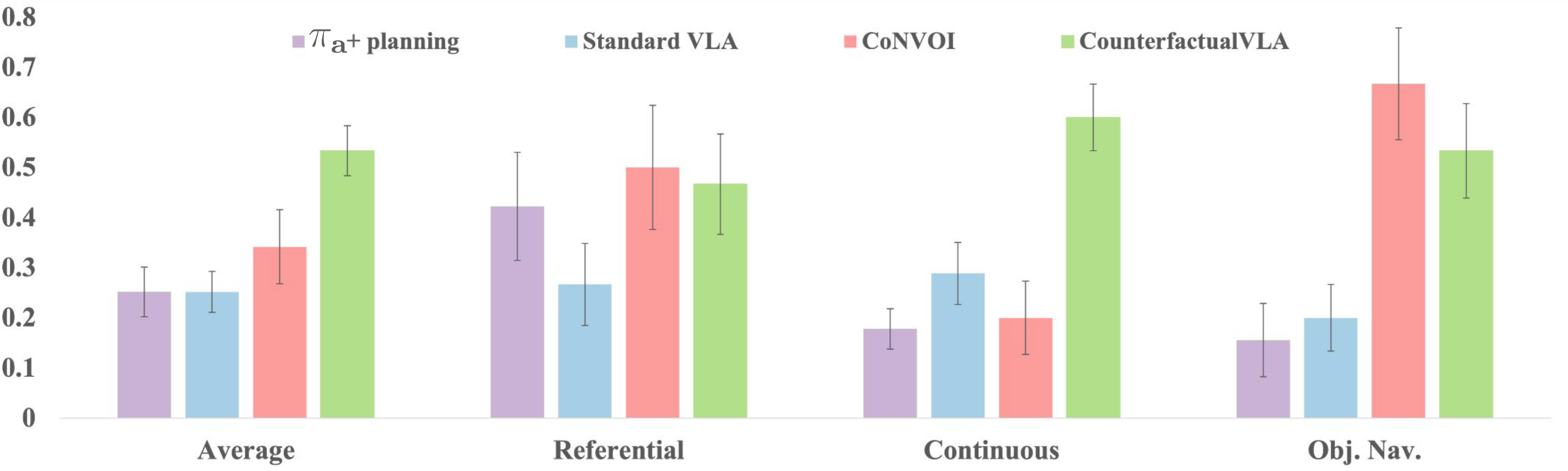
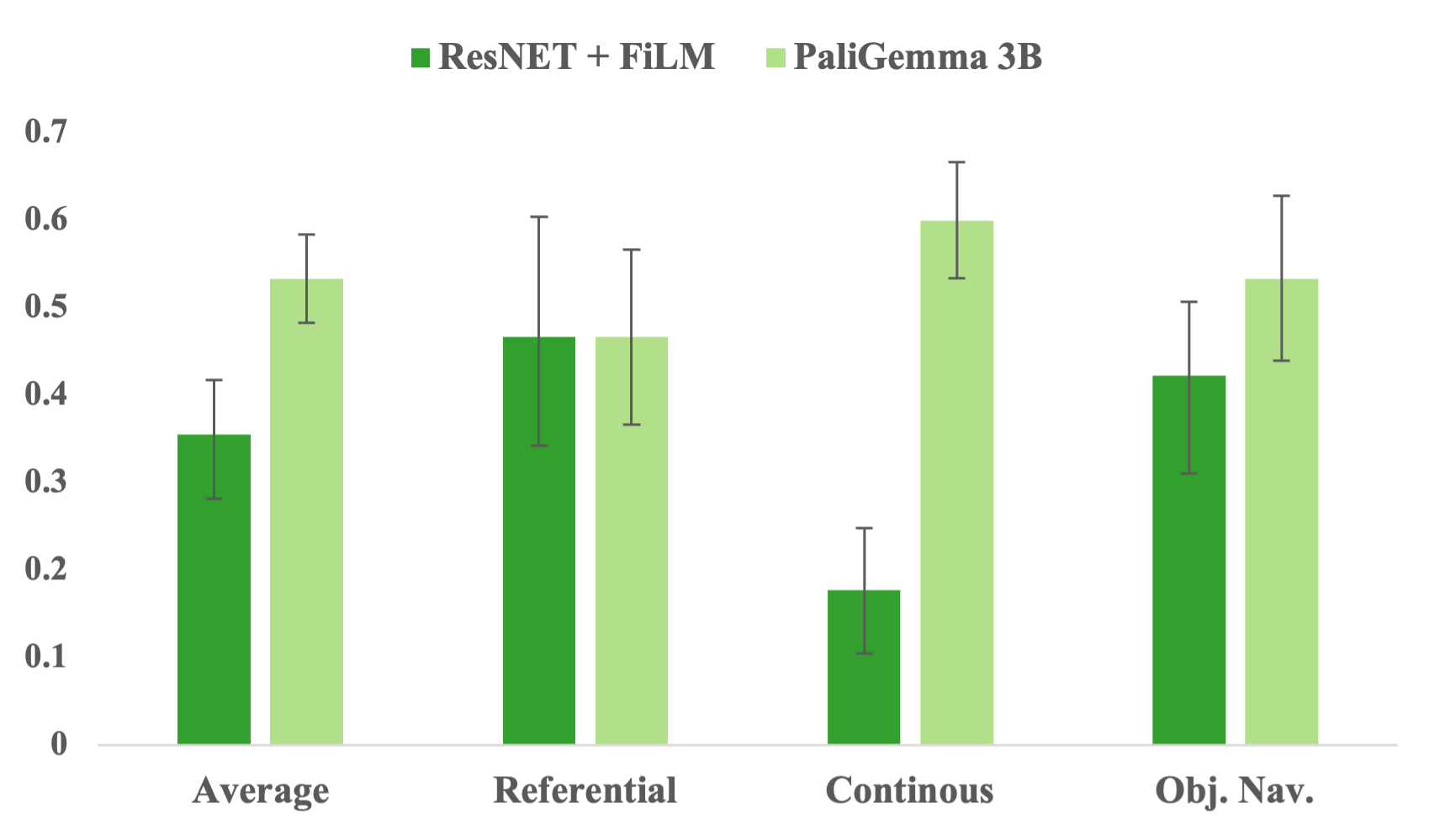
Approach
Counterfactual Augmentation with Synthetic Trajectories (CAST)
We propose CAST, Counterfactual Augmentation with Synthetic Trajectories, a method for both expanding and balancing the distribution of trajectories in your robotics dataset.
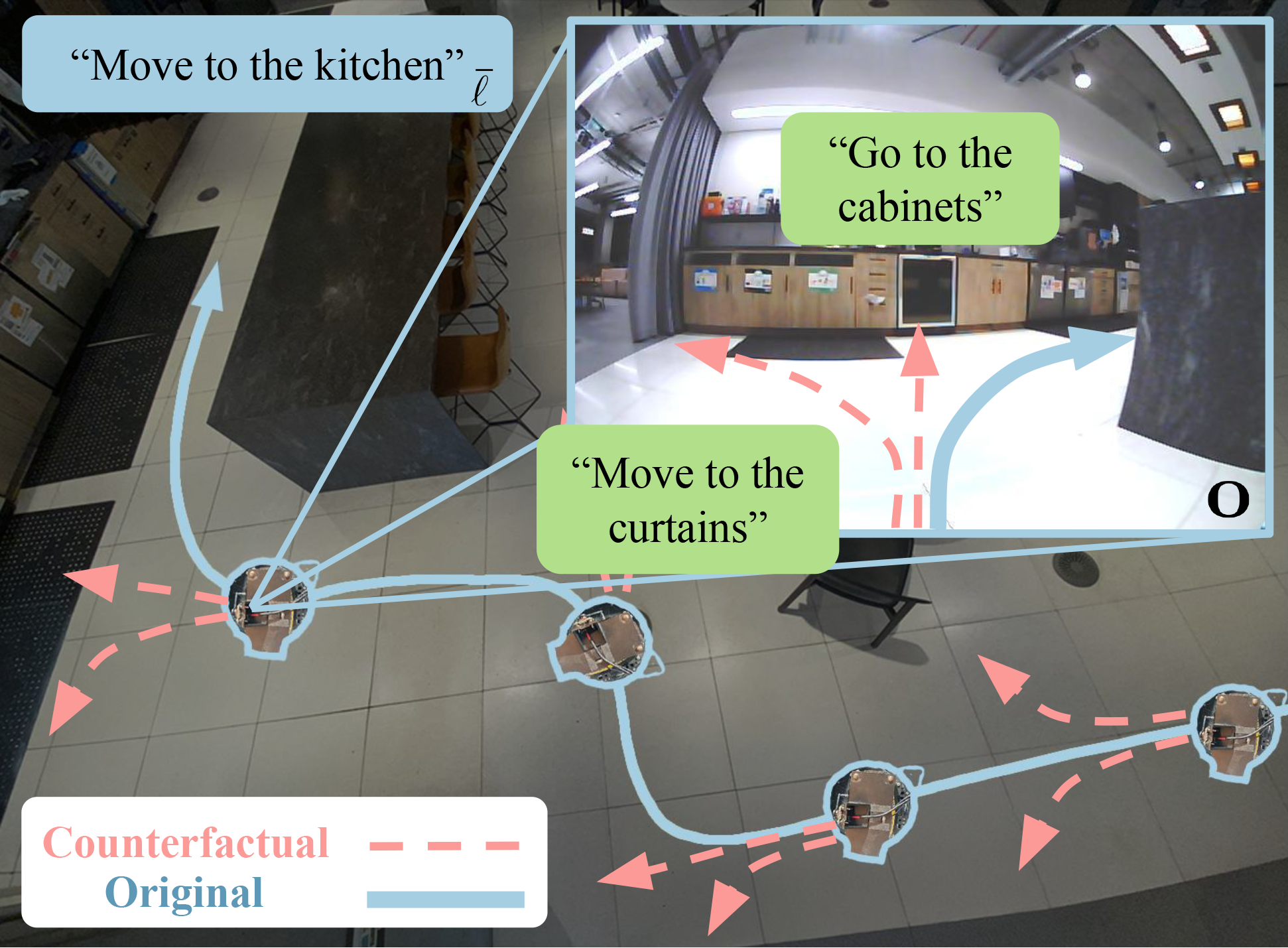
We observed that often VLA policies will learn to ignore language, especially when training on sufficiently diverse language instructions, as biases in the data result in the policy only needing to pay attention to the observation to predict the correct actions during training. Therefore, the goal of CAST is to expand the distribution of instructions and actions at any given observation. We show that this forces the model to attend to language, producing a more steerable policy.
CAST takes an uncurated robot dataset queries a VLM for counterfactual instructions that could have been executed at different points in the existing trajectories. The atomic command that aligns with the instruction is also determined and used to generate an action chunk. We can then append these counterfactual actions to the existing trajectory, creating the CAST dataset, which consists of both the original data and these counterfactual trajectory-instruction pairs. We use the CAST dataset to finetune PaliGemma-3B with the typical VLA recipe.